
Файл robots.txt – это текстовый файл, который используется для управления поведением поисковых систем и других роботов на веб-сайте. Он представляет собой инструкцию для поисковых роботов, указывая, какие страницы сайта нужно индексировать, а какие – игнорировать. Однако не все веб-мастера правильно создают и настраивают файл robots.txt, что может привести к нежелательным последствиям.
В данной статье рассмотрим 7 распространенных ошибок, которые веб-мастера часто допускают при создании файла robots.txt и приводят к проблемам с индексацией и видимостью веб-сайта в поисковых системах.
1. Неправильное имя файла
Первая и самая распространенная ошибка – неправильное имя файла. Файл robots.txt должен иметь именно такое имя, без пробелов и заглавных букв. Неправильное имя может привести к тому, что файл не будет распознан поисковыми роботами.
2. Неправильное расположение файла
Вторая ошибка – неправильное расположение файла. Файл robots.txt должен находиться в корневой директории сайта, т.е. в той же директории, где расположены файлы index.html и другие основные файлы сайта. Если файл находится в неправильной директории или не может быть обнаружен, то инструкции в нем также не будут выполняться.
3. Недостаточное количество инструкций
Третья ошибка – недостаточное количество инструкций в файле robots.txt. Иногда веб-мастера намеренно оставляют файл пустым или указывают только одну инструкцию, считая, что это достаточно. Однако, при этом веб-мастеры упускают возможность предоставить дополнительные инструкции для поисковых роботов.
Распространенные ошибки при создании файла robots.txt
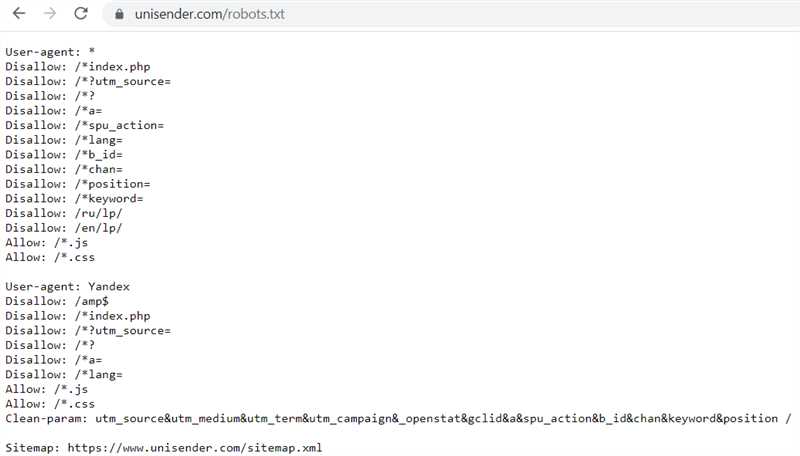
Вот несколько распространенных ошибок, которые следует избегать при создании файла robots.txt:
-
Неправильное указание пути к файлу роботов: Ошибка может возникнуть, если файл robots.txt находится в неправильной директории или его название указано неправильно. Убедитесь, что файл находится в корневой директории вашего сайта и его имя записано без ошибок.
-
Отсутствие правильной структуры файла: Файл robots.txt должен быть структурирован и легко читаем. Некорректное пользование комментариями, неправильная запись директив или их повторное использование может привести к ошибкам в работе роботов.
-
Забытые или неправильно указанные директивы: В файле robots.txt необходимо правильно указать директивы для разных разделов сайта. Например, если вы хотите запретить веб-паукам индексировать определенную страницу или директорию, не забудьте указать это в файле.
-
Неправильное использование мета-тега «noindex»: Использование мета-тега «noindex» в сочетании с файлом robots.txt может привести к противоречивым или неправильным указаниям для поисковых роботов. Поэтому, не рекомендуется использовать оба метода для одной и той же страницы или директории.
-
Отсутствие проверки файла на ошибки: После создания файла robots.txt рекомендуется проверить его на наличие ошибок. Существуют специальные инструменты, которые позволяют проверить корректность и правильность написания файла robots.txt.
Избегая эти распространенные ошибки, вы сможете создать правильный файл robots.txt, который будет эффективно управлять работой поисковых роботов на вашем сайте.
Не правильно указано местоположение файла robots.txt
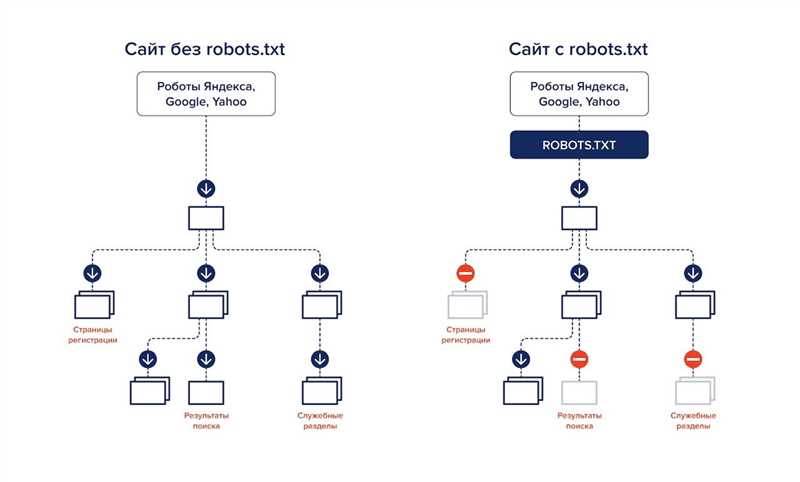
Чтобы файл robots.txt был доступен для поисковых роботов, он должен быть размещен в корневой директории вашего сайта. Это означает, что файл должен находиться в верхнем уровне директории, доступной по URL-адресу вашего сайта. Например, если ваш сайт доступен по адресу https://example.com, то файл robots.txt должен быть доступен по URL-адресу https://example.com/robots.txt.
Если файл robots.txt размещен в неправильной директории или его местоположение не указано правильно в файле .htaccess или другом механизме настройки сервера, поисковые роботы не смогут найти и прочитать его. Это может привести к нежелательному индексированию страниц, которые вы хотели бы скрыть от поисковых систем, а также к проблемам с индексацией и ранжированием вашего сайта в поисковых системах.
Для исправления этой ошибки необходимо убедиться, что файл robots.txt размещен в правильном месте на сервере и его местоположение указано верно. Также стоит проверить, что файл доступен по указанному URL-адресу и не блокируется сервером или другими механизмами.
Отказ от индексации всего сайта
В некоторых случаях владельцы сайтов могут сделать ошибку и отказаться от индексации всего сайта, используя файл robots.txt. Это может произойти по неосторожности или из-за неправильного понимания функции этого файла. Отказ от индексации всего сайта может иметь серьезные последствия для его видимости и поисковой оптимизации.
Основная функция файла robots.txt состоит в том, чтобы указать поисковым роботам, какие страницы сайта они могут индексировать. Имея доступ к этому файлу, роботы могут определить, какие страницы имеют открытый доступ и могут быть показаны в результатах поиска. Если владелец сайта запретит доступ к всем страницам, поисковые роботы не смогут найти их и, соответственно, не смогут индексировать их.
Существуют несколько причин, почему владелец сайта может внести такое ограничение. Некоторые из них могут быть обоснованными, например, временным запретом индексации во время проведения работы на сайте или тестирования новых страниц. Однако, в случае, когда владелец отказывается от индексации всего сайта на постоянной основе, это может привести к исключению его из поисковой выдачи.
Поисковые роботы не смогут узнать о наличии сайта и его содержимого, и пользователи не смогут найти его через поисковые системы. Это может сильно снизить видимость сайта, количество трафика и потенциальные возможности для продвижения. Владельцы сайтов должны быть внимательны при создании файла robots.txt и грамотно использовать его, чтобы сохранить видимость своего сайта в поисковых системах.
Неправильное использование директивы «Disallow»
Директива «Disallow» в файле robots.txt позволяет указывать поисковым роботам, какие страницы сайта им не стоит индексировать или сканировать. Однако, ее неправильное использование может привести к нежелательным последствиям и негативно повлиять на видимость и ранжирование сайта в поисковых системах.
Одной из распространенных ошибок является неправильное указание пути в директиве «Disallow». Нередко web-мастера случайно добавляют директиву с неверным путем, что может привести к заблокированию доступа поисковых роботов ко всему сайту. Поэтому перед добавлением директивы «Disallow» необходимо тщательно проверять путь к файлам или директориям, которые вы хотите заблокировать.
Другой ошибкой является использование директивы «Disallow» без необходимости. В некоторых случаях, web-мастера могут добавлять эту директиву для страниц, которые не требуют скрытия от поисковых роботов. Это может привести к ограничению индексации и сканирования важных страниц сайта, что отрицательно отразится на их ранжировании и поисковой видимости.
Важно также отметить, что директива «Disallow» имеет ограничения в использовании. Она может быть использована только для указания отдельных файлов или директорий, но не может быть применена к отдельным разделам или различным версиям сайта. Если вам необходимо заблокировать доступ к определенной части сайта, такой как административная панель или аккаунты пользователей, рекомендуется использовать другие способы, например, .htaccess или мета-теги «noindex, nofollow».
Таким образом, правильное использование директивы «Disallow» в файле robots.txt является важным элементом SEO-оптимизации. Неправильное указание пути, нежелательное использование или некорректное использование директивы «Disallow» может привести к нежелательным последствиям и ухудшить видимость и ранжирование сайта в поисковых системах. Поэтому перед внесением изменений в файл robots.txt рекомендуется тщательно проверять и анализировать все директивы и их пути, чтобы избежать возможных ошибок и проблем.
Наши партнеры: